

Compact Muon Solenoid
LHC, CERN
| CMS-PAS-MLG-23-001 | ||
| Portable Acceleration of CMS Production Workflow with Coprocessors as a Service | ||
| CMS Collaboration | ||
| 2 October 2023 | ||
| Abstract: Computing demands for large scientific experiments, such as the CMS experiment at CERN, will increase dramatically in the next decades. To complement the future performance increases of software running on CPUs, explorations of coprocessor usage in data processing hold great potential and interest. We explore the approach of Services for Optimized Network Inference on Coprocessors (SONIC) and study the deployment of this as-a-service approach in large-scale data processing. In the studies, we take a data processing workflow of the CMS experiment as an example, and run the main workflow on CPUs, while offloading several machine learning (ML) inference tasks onto either remote or local coprocessors, such as GPUs. With experiments performed at Google Cloud, the Purdue Tier-2 computing center, and combinations of the two, we demonstrate the acceleration of these ML algorithms individually on coprocessors and the corresponding throughput improvement for the entire workflow. This approach can be easily generalized to different types of coprocessors, and deployed on local CPUs without throughput performance decrease. We emphasize that SONIC enables high coprocessor usage and enables the portability to run workflows on different types of coprocessors. | ||
|
Links:
CDS record (PDF) ;
CADI line (restricted) ;
These preliminary results are superseded in this paper, Submitted to CSBS. The superseded preliminary plots can be found here. |
||
| Figures | |

png pdf |
Figure 1:
CPU time requirement projections for CMS offline processing and analysis needs [22,23]. The graph shows projected resource availability with a flat budget and an expected 10% to 20% decrease in computing costs. Lines are included for projections based on current performance and performance with expected research and development improvements. An analogous graph from ATLAS can be found in Ref. [24]. |
png pdf |
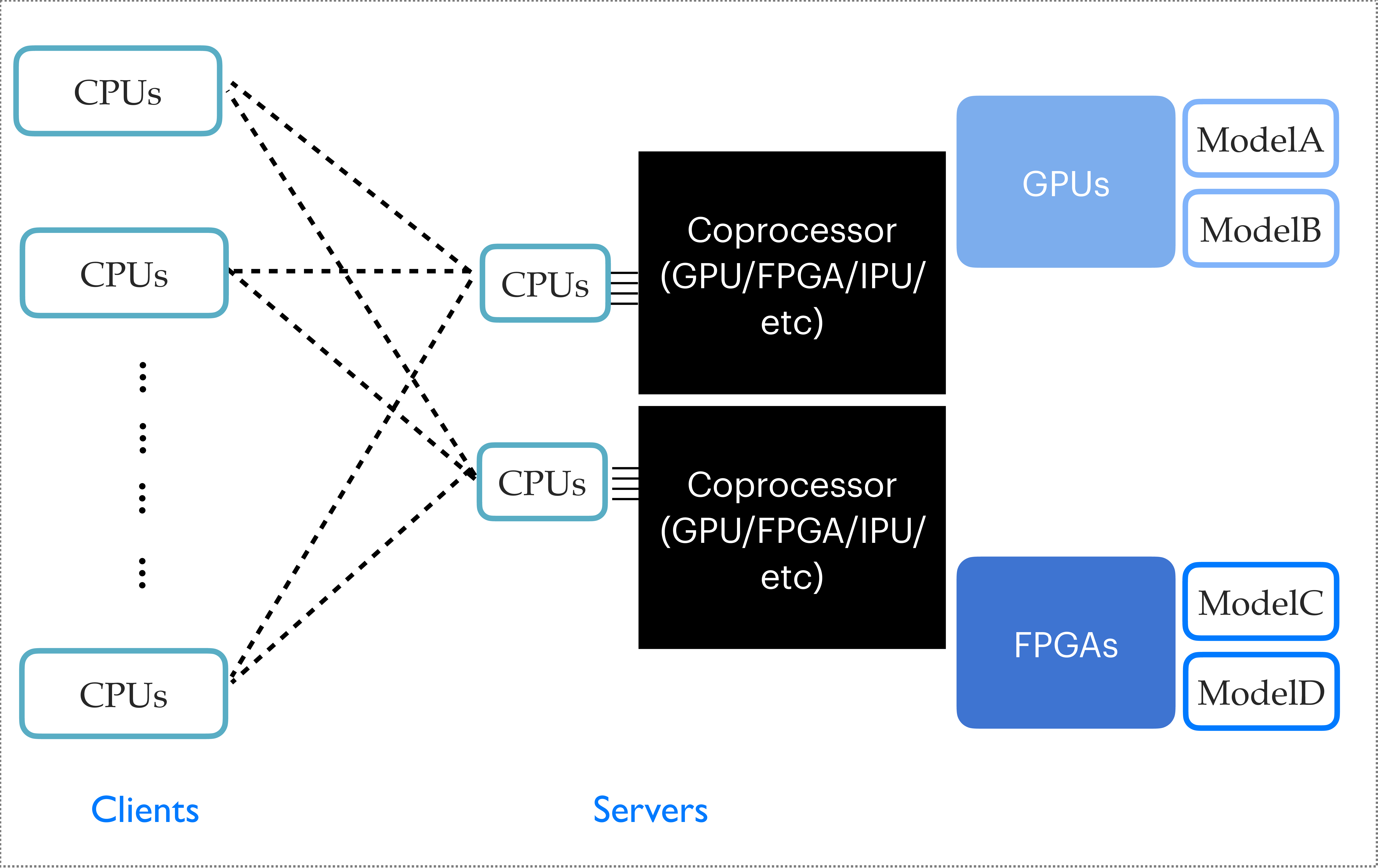
Figure 2:
An illustration of an example inference as-a-service setup with multiple coprocessor servers. ``Clients'' usually run on CPUs, shown on the left side; ``servers'' serving different models run on coprocessors, shown on the right side. |
png pdf |
Figure 3:
Illustration of the SONIC implementation of inference as-a-service in CMSSW. The figure also shows the possibility of an additional load-balancing layer in the SONIC scheme, for example, if multiple coprocessor-enabled machines are used to host servers, a Kubernetes engine can be set up to distribute inference calls across the machines. Image adapted from Ref. [66]. |

png pdf |
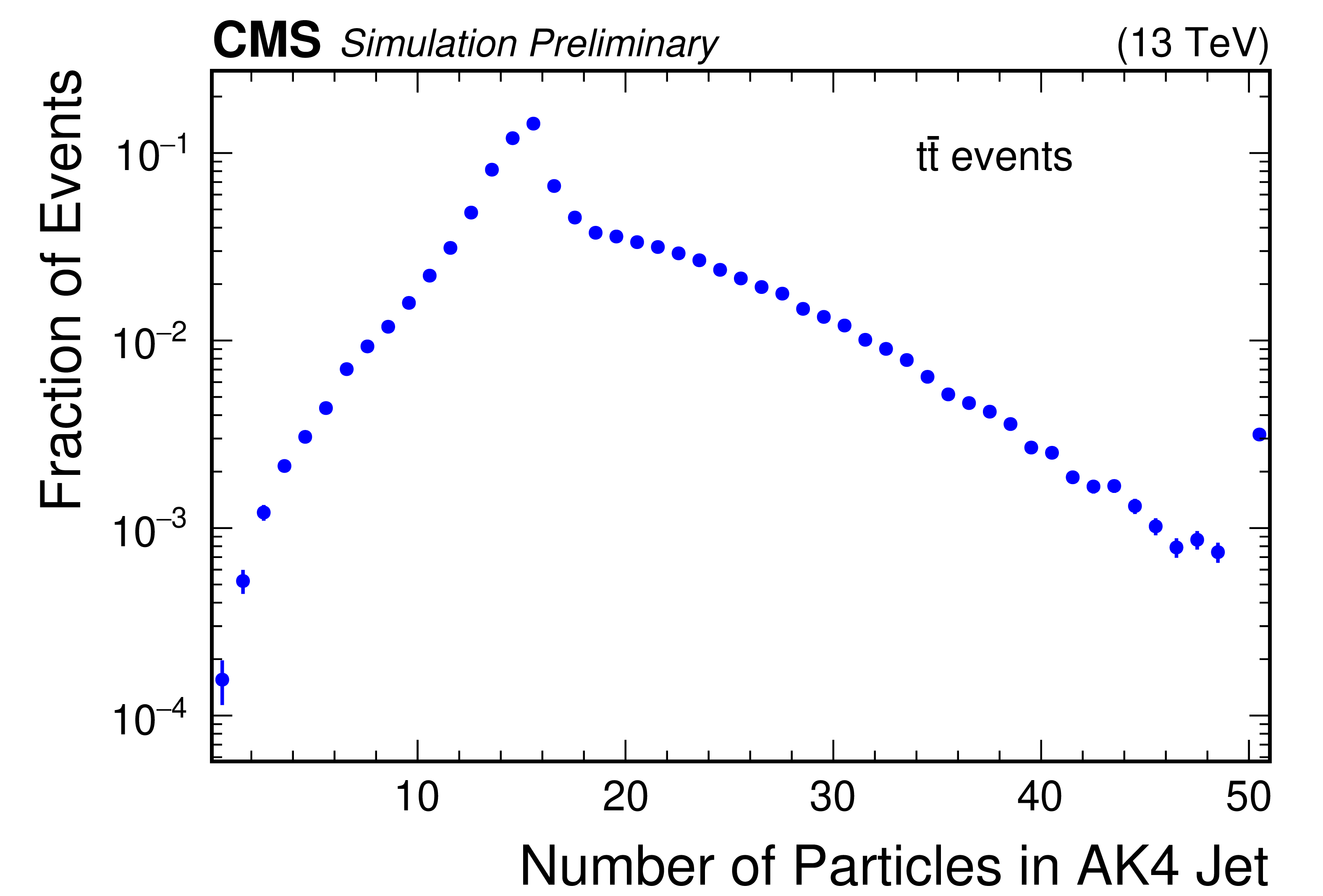
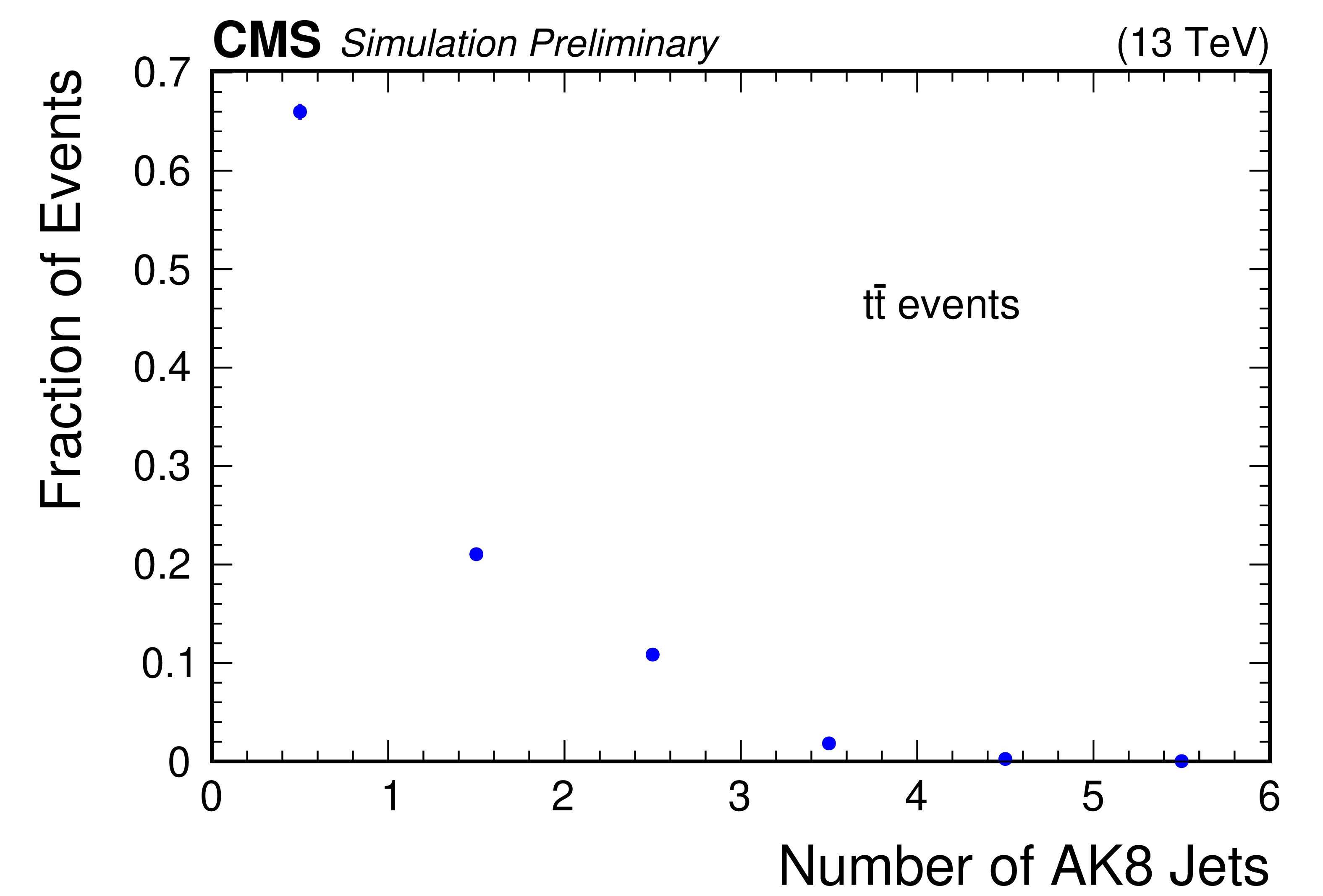
Figure 4:
Illustration of the jet information in Run 2 simulated $ \mathrm{t} \overline{\mathrm{t}} $ data set used in subsequent studies. The number per event (left), and distribution of the number of particles per jet (right) are shown for AK4 jets (top) and AK8 jets (bottom). For the distributions of the number of particles, the rightmost bin is an overflow bin. |

png pdf |
Figure 4-a:
Illustration of the jet information in Run 2 simulated $ \mathrm{t} \overline{\mathrm{t}} $ data set used in subsequent studies. The number per event (left), and distribution of the number of particles per jet (right) are shown for AK4 jets (top) and AK8 jets (bottom). For the distributions of the number of particles, the rightmost bin is an overflow bin. |
png pdf |
Figure 4-b:
Illustration of the jet information in Run 2 simulated $ \mathrm{t} \overline{\mathrm{t}} $ data set used in subsequent studies. The number per event (left), and distribution of the number of particles per jet (right) are shown for AK4 jets (top) and AK8 jets (bottom). For the distributions of the number of particles, the rightmost bin is an overflow bin. |
png pdf |
Figure 4-c:
Illustration of the jet information in Run 2 simulated $ \mathrm{t} \overline{\mathrm{t}} $ data set used in subsequent studies. The number per event (left), and distribution of the number of particles per jet (right) are shown for AK4 jets (top) and AK8 jets (bottom). For the distributions of the number of particles, the rightmost bin is an overflow bin. |
png pdf |
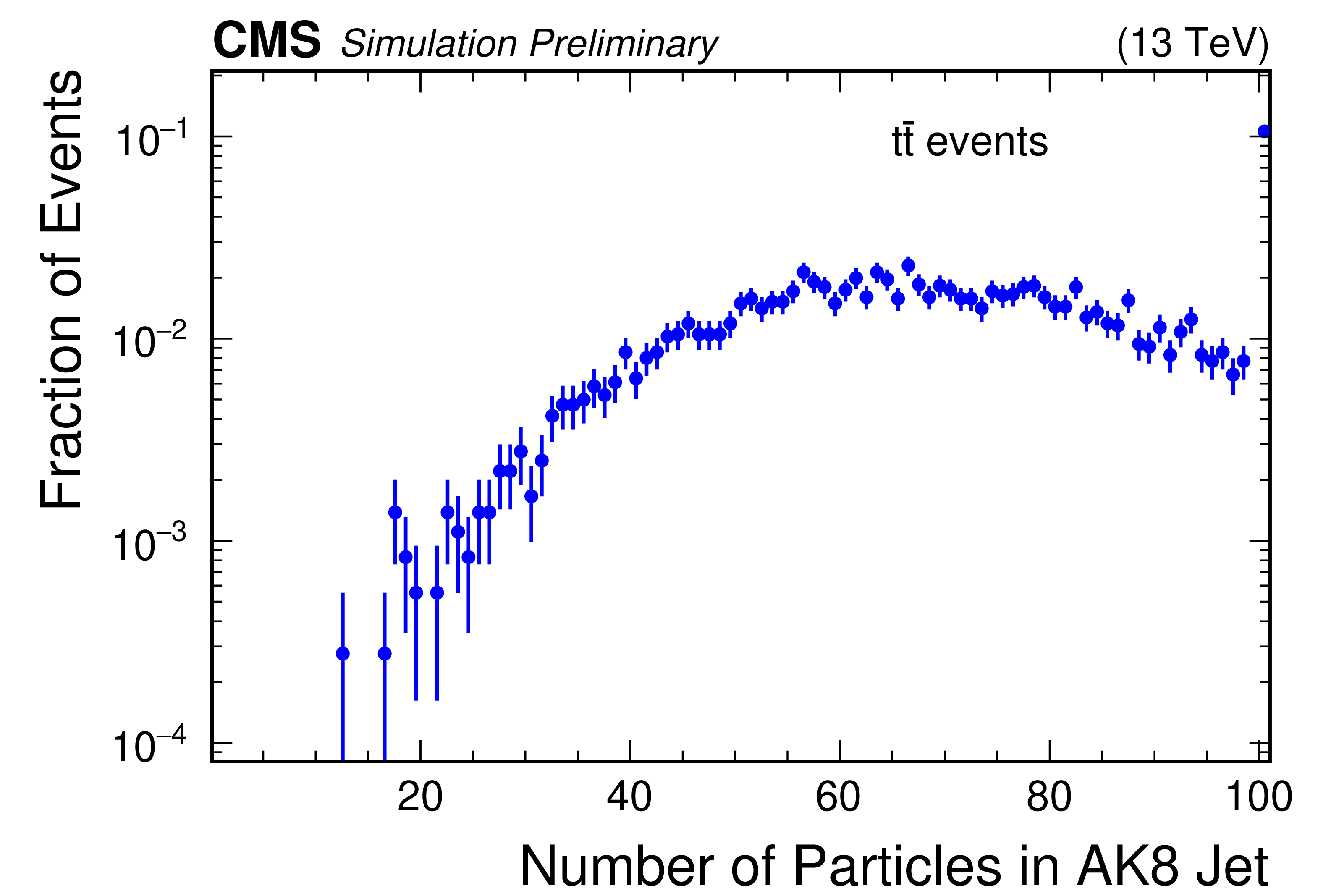
Figure 4-d:
Illustration of the jet information in Run 2 simulated $ \mathrm{t} \overline{\mathrm{t}} $ data set used in subsequent studies. The number per event (left), and distribution of the number of particles per jet (right) are shown for AK4 jets (top) and AK8 jets (bottom). For the distributions of the number of particles, the rightmost bin is an overflow bin. |
png pdf |
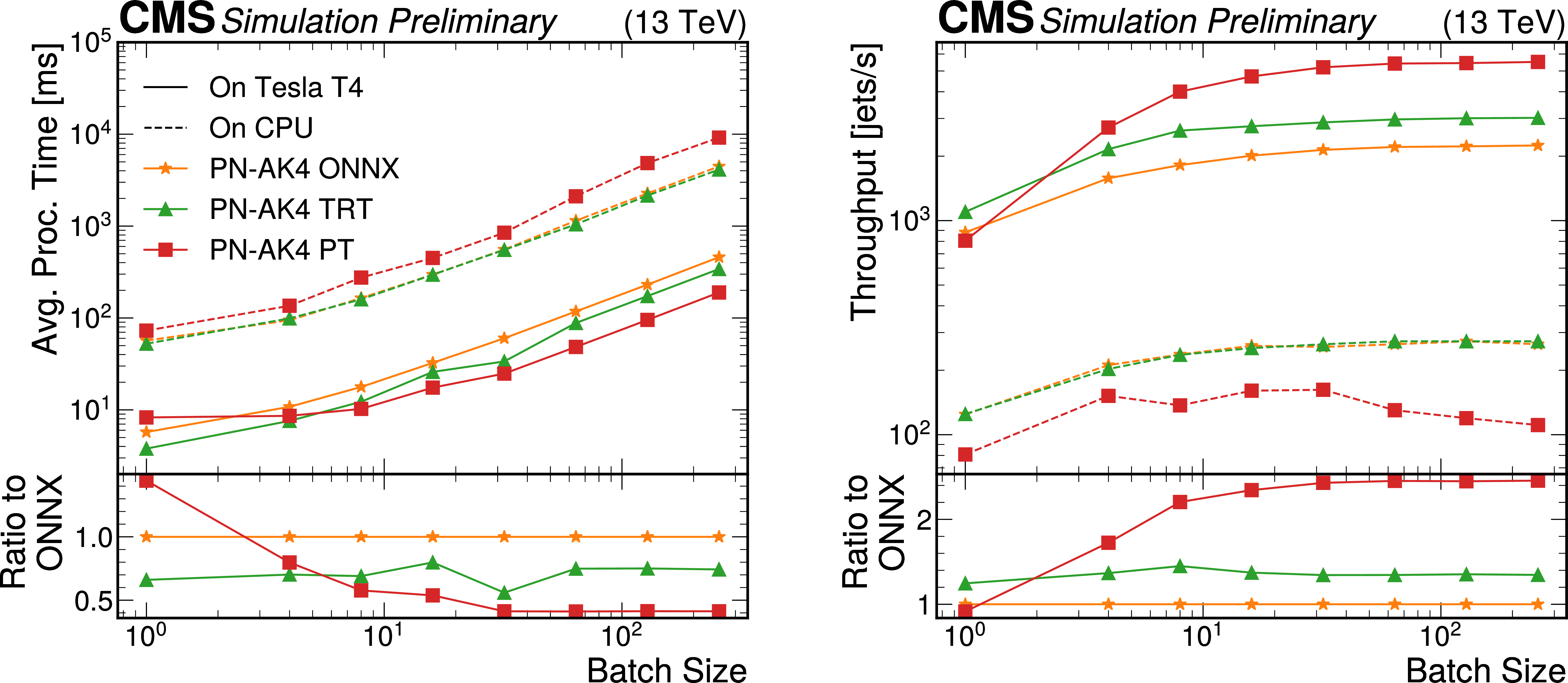
Figure 5:
Average processing time (left) and throughput (right) of the PN-AK4 algorithm served by a TRITON server running on one NVIDIA Tesla T4 GPU, presented as a function of the batch size. Values are shown for different inference backends: ONNX (orange), ONNX with TENSORRT (green), and PYTORCH (red). Performance values for these backends when running on a CPU-based TRITON server are given in dashed lines, with the same color-to-backend correspondence. |
png pdf |
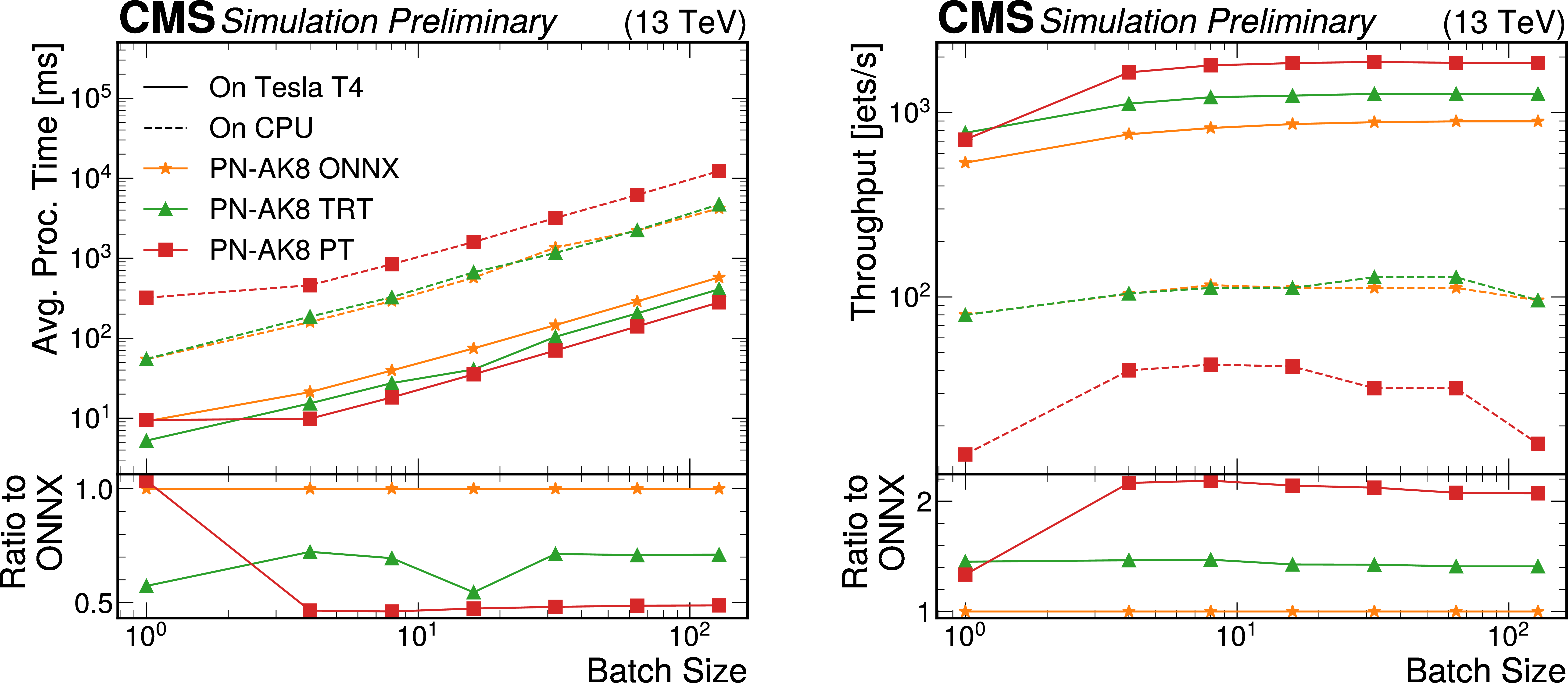
Figure 6:
Average processing time (left) and throughput (right) of one of the AK8 ParticleNet algorithms served by a TRITON server running on one NVIDIA Tesla T4 GPU, presented as a function of the batch size. Values are shown for different inference backends: ONNX (orange), ONNX with TENSORRT (green), and PYTORCH (red). Performance values for these backends when running on a CPU-based TRITON server are given in dashed lines, with the same color-to-backend correspondence. |

png pdf |
Figure 7:
Average processing time (left) and throughput (right) of the DeepMET algorithm served by a TRITON server running on one NVIDIA Tesla T4 GPU, presented as a function of the batch size. Similar performance when running on a CPU-based TRITON server is given in dashed lines, with the same color-to-backend correspondence. |

png pdf |
Figure 8:
Average processing time (left) and throughput (right) of the DeepTau algorithm served by a TRITON server running on one NVIDIA Tesla T4 GPU, presented as a function of the batch size. Values are shown for different inference backends: TENSORFLOW (orange), and TENSORFLOW with TENSORRT (blue). Performance values for these backends when running on a CPU-based TRITON server are given in dashed lines, with the same color-to-backend correspondence. |
png pdf |
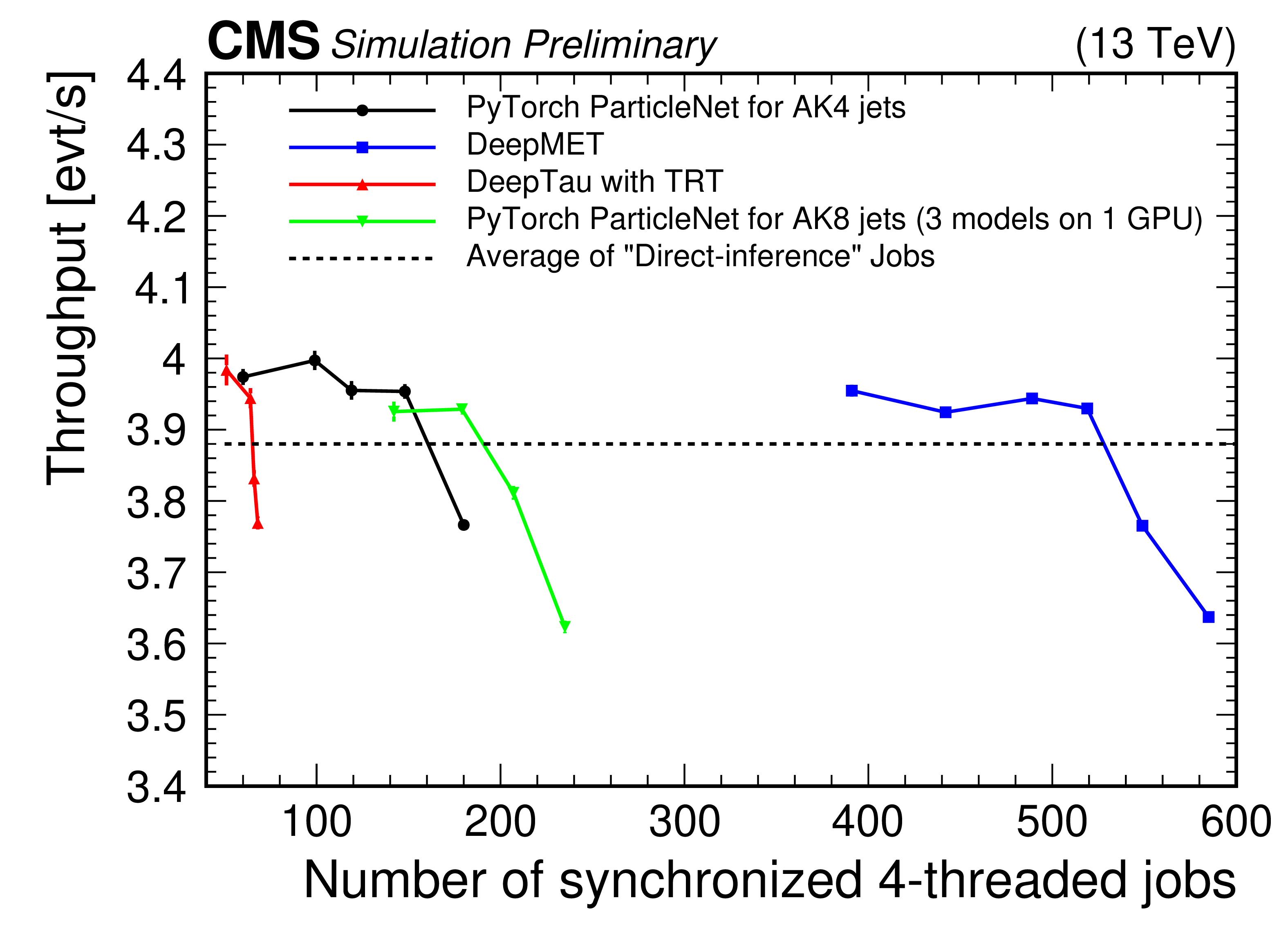
Figure 9:
GPU saturation scan performed in GCP, where the per-event throughput is shown as a function of the number of parallel CPU clients for the PYTORCH version of ParticleNet for AK4 jets (black), DeepMET (blue), DeepTau optimized with TRT (red), and all PYTORCH versions of ParticleNet for AK8 jets on a single GPU (green). Each of the parallel jobs was run in a 4-threaded configuration. The CPU tasks ran in 4-threaded GCP VMs, and the TRITON servers were hosted on separate single GPU VMs also in GCP. The line for ``direct-inference'' jobs represents the baseline configuration measured by running all algorithms without the use of SONIC or any GPUs. Each solid line represents running one of the specified models on GPU via SONIC. |
png pdf |
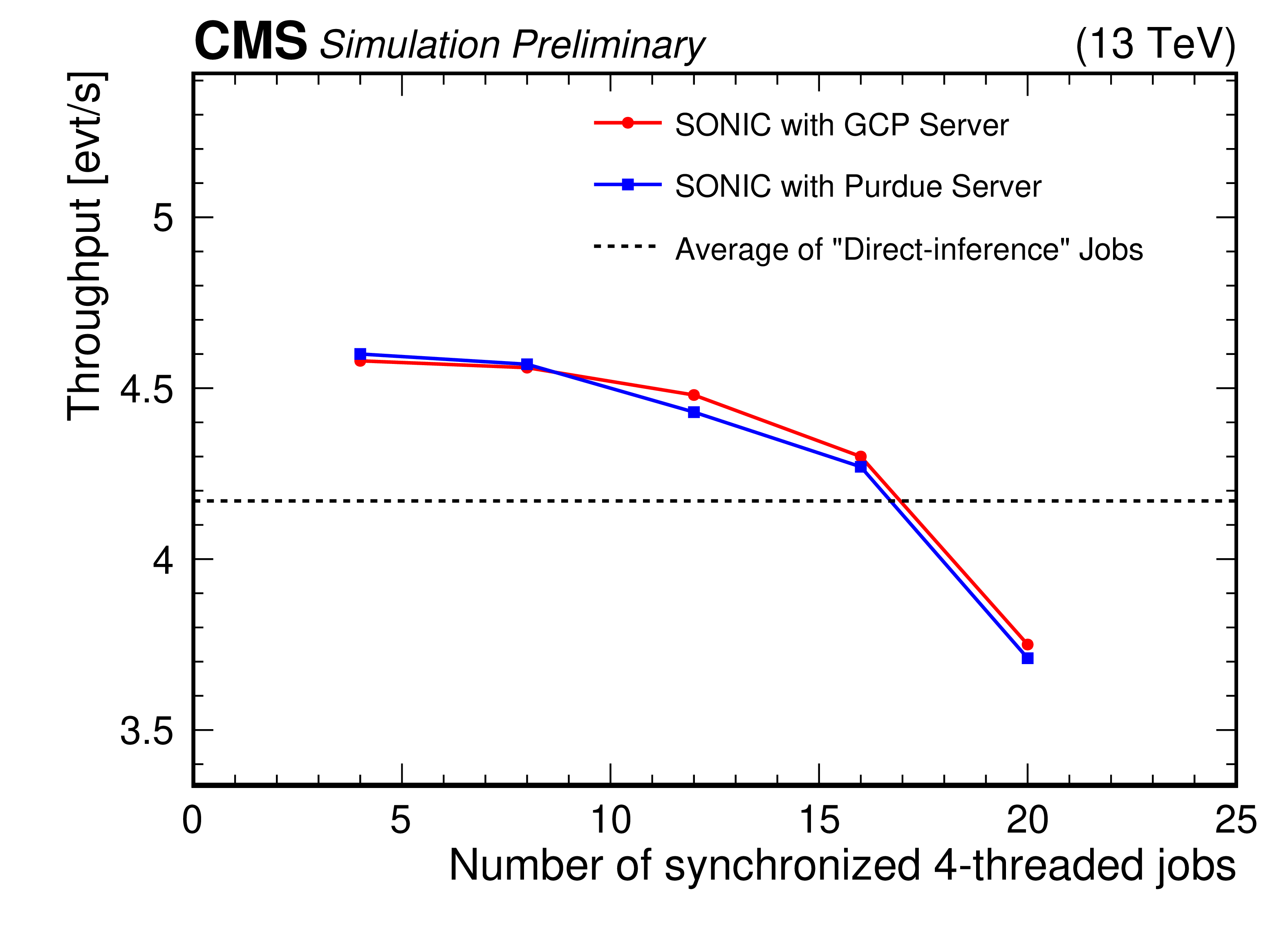
Figure 10:
Production tests across different sites. The CPU tasks run at Purdue, while the servers with GPU inference tasks run at Purdue (blue) and at GCP (red). The throughput values are higher than those shown in Fig. 8 because the CPUs at Purdue are more powerful than those comprising the GCP VMs. |
png pdf |
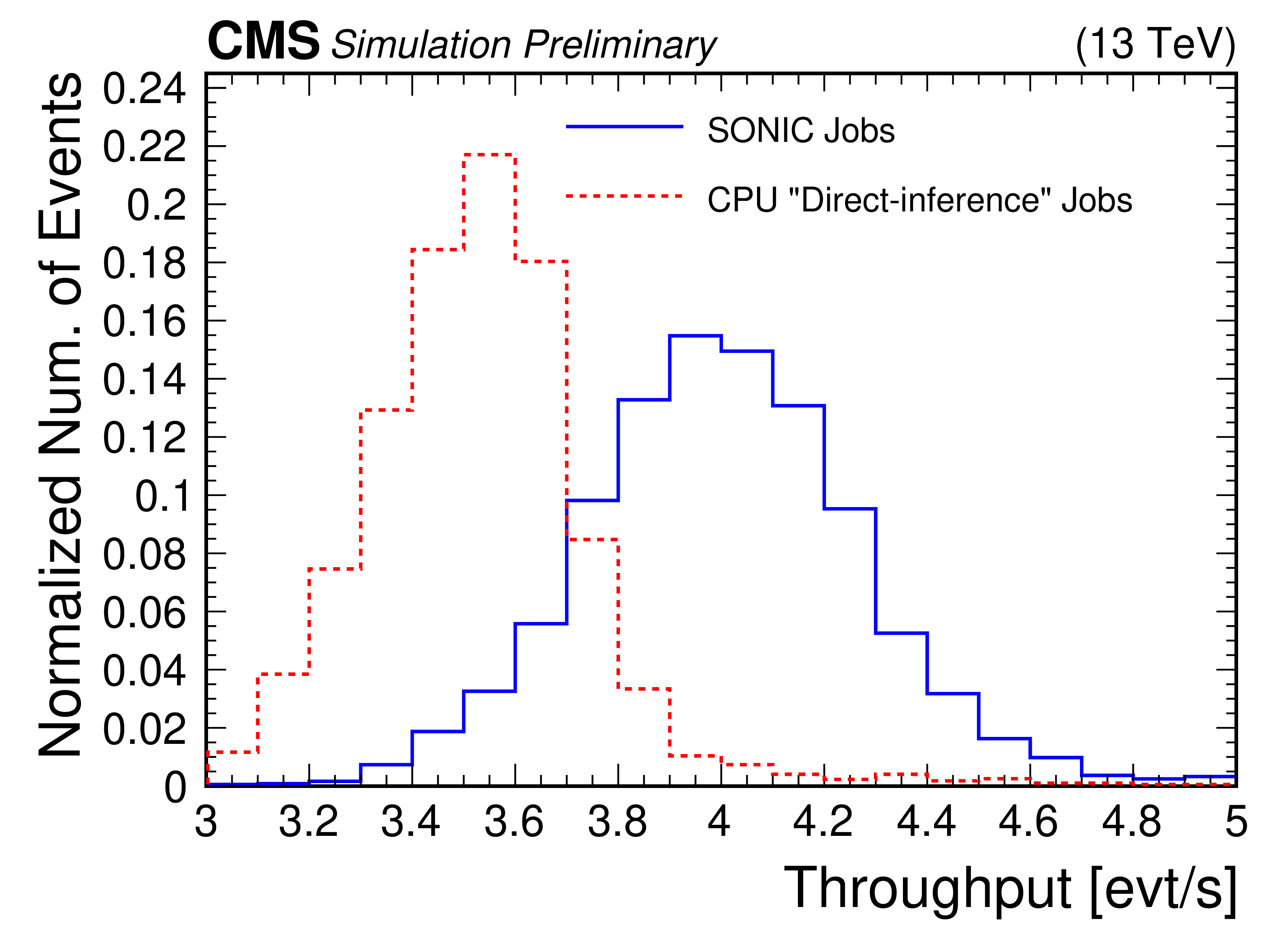
Figure 11:
Scale-out test results on Google Cloud. The average throughput of the SONIC-enabled workflow was 4.01 events per second, while the average throughput of the ``direct-inference" workflow is 3.52 events per second (dashed red) with a variance of around 2%. The SONIC-enabled workflow thus achieves a throughput that is 13% larger than the CPU-only version of the workflow. |
png pdf |
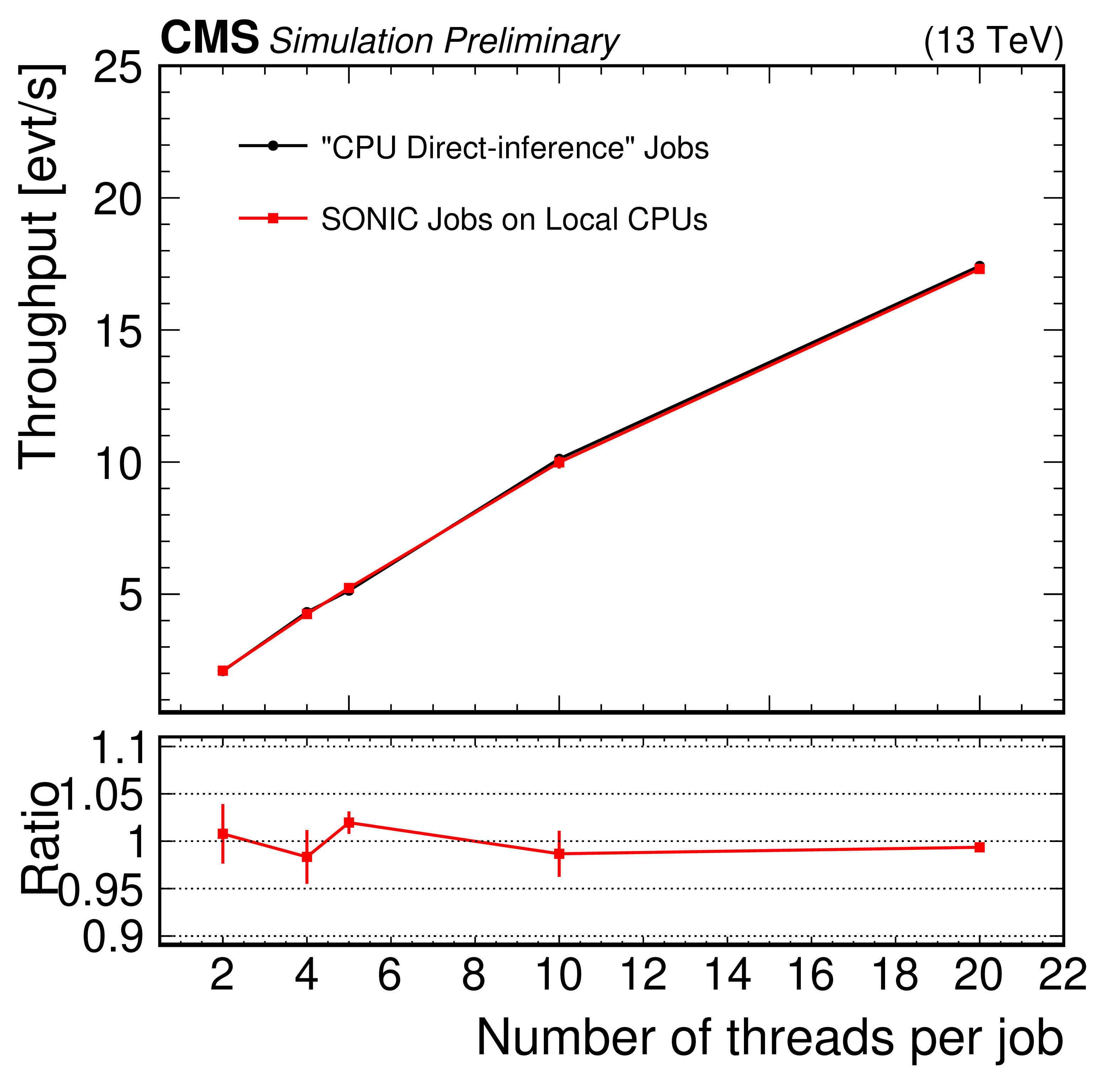
Figure 12:
Throughput (top) and throughput ratios (bottom) between SONIC and direct inference in the local CPU tests at Purdue Tier-2 cluster. To ensure the CPUs are always saturated, the number of threads per job multiplied by the number of jobs is set to 20. |
| Tables | |

png pdf |
Table 1:
Average event size of different CMS data tiers for $ \mathrm{t} \overline{\mathrm{t}} $ events with Run 2 configuration and pileup conditions [52,62]. |
png pdf |
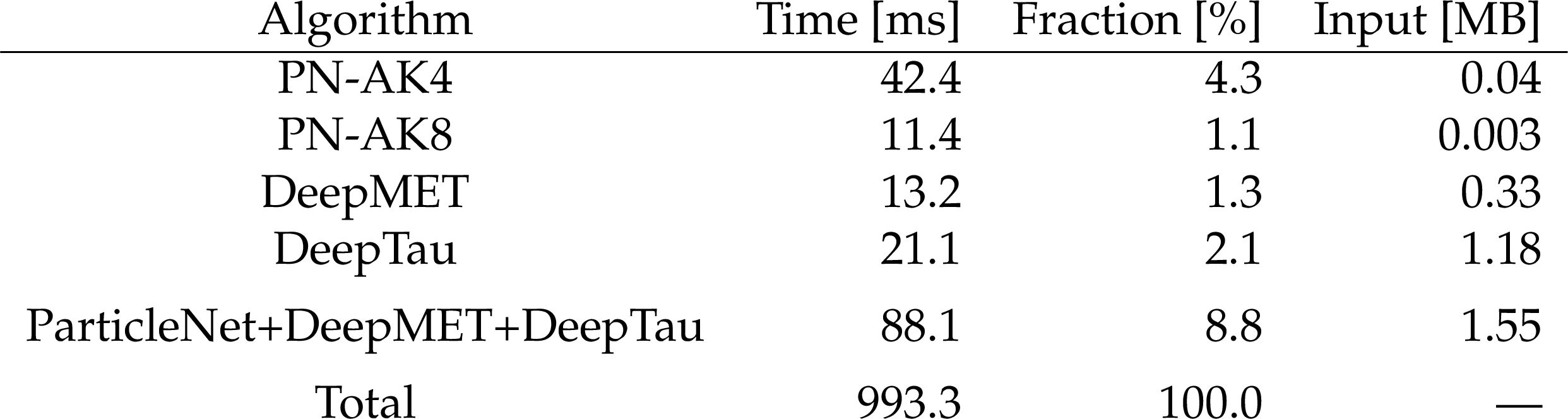
Table 2:
The average processing time of the Mini-AOD processing (without SONIC). The average processing time of the algorithms for which a SONIC version was created are stated explicitly. They consume about 9% of the total processing time. This table also contains the expected server input for each model type created per event in Run 2 $ \mathrm{t} \overline{\mathrm{t}} $ events. |

png pdf |
Table 3:
Memory usage with direct inferences and SONIC in the local CPU tests at Purdue Tier-2 cluster. To ensure the CPUs are always saturated, the number of threads per job multiplied by the number of jobs is set to 20. |
| Summary |
| Within the next decade, the data-taking rate at the LHC will increase dramatically, straining the expected computing resources of the LHC experiments. At the same time, more algorithms that run on these resources will be converted into either machine learning or domain algorithms that are easily accelerated with the use of coprocessors, such as graphics processing units (GPUs). By pursuing heterogeneous architectures, it is possible to alleviate potential shortcomings of available central processing unit (CPU) resources. Inference as a service (IaaS) is a promising scheme to integrate coprocessors into CMS computing workflows. In IaaS, client code simply assembles the input data for an algorithm, sends that input to an inference server running either locally or remotely, and retrieves output from the server. The implementation of IaaS discussed throughout this note is called Services for Optimized Network Inference on Coprocessors (SONIC). SONIC employs NVIDIA TRITON Inference Servers to host models on coprocessors, as demonstrated here in studies on GPUs, CPUs, and Graphcore Intelligence Processing Units (IPUs). In this note, the use of SONIC in the CMS software framework (CMSSW) is demonstrated in a sample Mini-AOD workflow, where algorithms for jet tagging, tau lepton identification, and missing transverse momentum regression are ported to run on inference servers. These algorithms account for 10% of the total processing time per event in a simulated sample of top quark-antiquark events. After model profiling, which is used to optimize server performance and determine the needed number of GPUs for a given number of client jobs, the expected 10% decrease in per-event processing time was achieved in a large-scale test of SONIC-enabled Mini-AOD production that used about 10,000 CPU cores and 100 GPUs. The network bandwidth is large enough to support high input-output model inferences for the workflow tested, and will be monitored as the fraction of algorithms using remote GPUs increases. In addition to meeting performance expectations, we demonstrated that the throughput results are not highly sensitive to the physical client-to-server distance and that running inference through TRITON servers on local CPU resources does not affect the throughput compared with the standard approach of running inference directly on CPUs in the job thread. We also performed a test using GraphCore IPUs to demonstrate the flexibility of the SONIC approach. The SONIC approach for IaaS represents a flexible approach to accelerate algorithms, which is increasingly valuable for LHC experiments. Using a realistic workflow, we highlighted many of SONIC's benefits, including the use of remote resources, workflow acceleration, and portability to different processor technologies. To make it a viable and robust paradigm for CMS computing in the future, additional studies are ongoing or planned for monitoring and mitigating potential issues such as excessive network and memory usage or server failures. |
| References | ||||
| 1 | L. Evans and P. Bryant | LHC Machine | JINST 3 (2008) S08001 | |
| 2 | ATLAS Collaboration | The ATLAS Experiment at the CERN Large Hadron Collider | JINST 3 (2008) S08003 | |
| 3 | CMS Collaboration | The CMS Experiment at the CERN LHC | JINST 3 (2008) S08004 | |
| 4 | ATLAS Collaboration | Observation of a new particle in the search for the Standard Model Higgs boson with the ATLAS detector at the LHC | PLB 716 (2012) 1 | 1207.7214 |
| 5 | CMS Collaboration | Observation of a New Boson at a Mass of 125 GeV with the CMS Experiment at the LHC | PLB 716 (2012) 30 | CMS-HIG-12-028 1207.7235 |
| 6 | CMS Collaboration | Observation of a new boson with mass near 125 GeV in pp collisions at $ \sqrt{s} = $ 7 and 8 TeV | JHEP 06 (2013) 081 | CMS-HIG-12-036 1303.4571 |
| 7 | ATLAS Collaboration | Search for new phenomena in events with two opposite-charge leptons, jets and missing transverse momentum in pp collisions at $ \sqrt{\mathrm{s}} = $ 13 TeV with the ATLAS detector | JHEP 04 (2021) 165 | 2102.01444 |
| 8 | ATLAS Collaboration | Search for squarks and gluinos in final states with one isolated lepton, jets, and missing transverse momentum at $ \sqrt{s}= $ 13 TeV with the ATLAS detector | EPJC 81 (2021) 600 | 2101.01629 |
| 9 | ATLAS Collaboration | Search for new phenomena in events with an energetic jet and missing transverse momentum in $ pp $ collisions at $ \sqrt {s} = $ 13 TeV with the ATLAS detector | PRD 103 (2021) 112006 | 2102.10874 |
| 10 | CMS Collaboration | Search for supersymmetry in proton-proton collisions at $ \sqrt{s} = $ 13 TeV in events with high-momentum Z bosons and missing transverse momentum | JHEP 09 (2020) 149 | CMS-SUS-19-013 2008.04422 |
| 11 | CMS Collaboration | Search for supersymmetry in final states with two or three soft leptons and missing transverse momentum in proton-proton collisions at $ \sqrt{s} = $ 13 TeV | JHEP 04 (2022) 091 | CMS-SUS-18-004 2111.06296 |
| 12 | CMS Collaboration | Search for higgsinos decaying to two Higgs bosons and missing transverse momentum in proton-proton collisions at $ \sqrt{s} = $ 13 TeV | JHEP 05 (2022) 014 | CMS-SUS-20-004 2201.04206 |
| 13 | ATLAS Collaboration | Search for single production of a vectorlike $ T $ quark decaying into a Higgs boson and top quark with fully hadronic final states using the ATLAS detector | PRD 105 (2022) 092012 | 2201.07045 |
| 14 | ATLAS Collaboration | Search for new phenomena in three- or four-lepton events in $ pp $ collisions at $ \sqrt s = $ 13 TeV with the ATLAS detector | PLB 824 (2022) 136832 | 2107.00404 |
| 15 | CMS Collaboration | Search for resonant and nonresonant production of pairs of dijet resonances in proton-proton collisions at $ \sqrt{s} = $ 13 TeV | JHEP 07 (2023) 161 | CMS-EXO-21-010 2206.09997 |
| 16 | CMS Collaboration | Search for long-lived particles decaying to a pair of muons in proton-proton collisions at $ \sqrt{s} = $ 13 TeV | JHEP 05 (2023) 228 | CMS-EXO-21-006 2205.08582 |
| 17 | O. Brüning and L. Rossi, eds. | The High Luminosity Large Hadron Collider: the new machine for illuminating the mysteries of Universe | World Scientific, 2015 link |
|
| 18 | CMS Collaboration | The Phase-2 Upgrade of the CMS Level-1 Trigger | CMS Technical Design Report CERN-LHCC-2020-004, CMS-TDR-021, 2020 CDS |
|
| 19 | ATLAS Collaboration | Technical Design Report for the Phase-II Upgrade of the ATLAS TDAQ System | ATLAS Technical Design Report CERN-LHCC-2017-020, ATLAS-TDR-029, 2017 link |
|
| 20 | ATLAS Collaboration | Operation of the ATLAS trigger system in Run 2 | JINST 15 (2020) P10004 | 2007.12539 |
| 21 | CMS Collaboration | The CMS trigger system | JINST 12 (2017) P01020 | CMS-TRG-12-001 1609.02366 |
| 22 | CMS Collaboration | The Phase-2 Upgrade of the CMS Data Acquisition and High Level Trigger | CMS Technical Design Report CERN-LHCC-2021-007, CMS-TDR-022, 2021 CDS |
|
| 23 | CMS Offline Software and Computing | CMS Phase-2 Computing Model: Update Document | CMS Note CMS-NOTE-2022-008, CERN-CMS-NOTE-2022-008, 2022 | |
| 24 | ATLAS Collaboration | ATLAS Software and Computing HL-LHC Roadmap | LHCC Public Document CERN-LHCC-2022-005, LHCC-G-182, 2022 | |
| 25 | D. Guest, K. Cranmer, and D. Whiteson | Deep Learning and its Application to LHC Physics | Ann. Rev. Nucl. Part. Sci. 68 (2018) 161 | 1806.11484 |
| 26 | K. Albertsson et al. | Machine Learning in High Energy Physics Community White Paper | JPCS 1085 (2018) 022008 | 1807.02876 |
| 27 | D. Bourilkov | Machine and Deep Learning Applications in Particle Physics | Int. J. Mod. Phys. A 34 (2020) 1930019 | 1912.08245 |
| 28 | A. J. Larkoski, I. Moult, and B. Nachman | Jet Substructure at the Large Hadron Collider: A Review of Recent Advances in Theory and Machine Learning | Phys. Rept. 841 (2020) 1 | 1709.04464 |
| 29 | HEP ML Community | A Living Review of Machine Learning for Particle Physics | 2102.02770 | |
| 30 | P. Harris et al. | Physics Community Needs, Tools, and Resources for Machine Learning | in Proceedings of the 2021 US Community Study on the Future of Particle Physics, 2022 link |
2203.16255 |
| 31 | S. Farrell et al. | Novel deep learning methods for track reconstruction | in 4th, 2018 International Workshop Connecting The Dots 201 (2018) 8 |
1810.06111 |
| 32 | S. Amrouche et al. | The Tracking Machine Learning challenge: Accuracy phase | link | 1904.06778 |
| 33 | X. Ju et al. | Performance of a geometric deep learning pipeline for HL-LHC particle tracking | EPJC 81 (2021) 876 | 2103.06995 |
| 34 | G. DeZoort et al. | Charged Particle Tracking via Edge-Classifying Interaction Networks | Comput. Softw. Big Sci. 5 (2021) 26 | 2103.16701 |
| 35 | S. R. Qasim, J. Kieseler, Y. Iiyama, and M. Pierini | Learning representations of irregular particle-detector geometry with distance-weighted graph networks | EPJC 79 (2019) 608 | 1902.07987 |
| 36 | J. Kieseler | Object condensation: one-stage grid-free multi-object reconstruction in physics detectors, graph and image data | EPJC 80 (2020) 886 | 2002.03605 |
| 37 | CMS Collaboration | GNN-based end-to-end reconstruction in the CMS Phase 2 High-Granularity Calorimeter | JPCS 2438 (2023) 012090 | 2203.01189 |
| 38 | J. Pata et al. | MLPF: Efficient machine-learned particle-flow reconstruction using graph neural networks | EPJC 81 (2021) 381 | 2101.08578 |
| 39 | CMS Collaboration | Machine Learning for Particle Flow Reconstruction at CMS | JPCS 2438 (2023) 012100 | 2203.00330 |
| 40 | F. Mokhtar et al. | Progress towards an improved particle flow algorithm at CMS with machine learning | in 21st International Workshop on Advanced Computing and Analysis Techniques in Physics Research: AI meets Reality, 2023 | 2303.17657 |
| 41 | E. A. Moreno et al. | JEDI-net: a jet identification algorithm based on interaction networks | EPJC 80 (2020) 58 | 1908.05318 |
| 42 | H. Qu and L. Gouskos | ParticleNet: Jet Tagging via Particle Clouds | PRD 101 (2020) 056019 | 1902.08570 |
| 43 | E. A. Moreno et al. | Interaction networks for the identification of boosted $ H\to b\overline{b} $ decays | PRD 102 (2020) 012010 | 1909.12285 |
| 44 | CMS Collaboration | Identification of heavy, energetic, hadronically decaying particles using machine-learning techniques | JINST 15 (2020) P06005 | CMS-JME-18-002 2004.08262 |
| 45 | J. Duarte et al. | FPGA-accelerated machine learning inference as a service for particle physics computing | Comput. Softw. Big Sci. 3 (2019) 13 | 1904.08986 |
| 46 | D. Rankin et al. | FPGAs-as-a-service toolkit (FaaST) | in IEEE/ACM International Workshop on Heterogeneous High-performance Reconfigurable Computing (H2RC). IEEE, 2020 link |
|
| 47 | J. Krupa et al. | GPU coprocessors as a service for deep learning inference in high energy physics | Mach. Learn. Sci. Tech. 2 (2021) 035005 | 2007.10359 |
| 48 | ALICE Collaboration | Real-time data processing in the ALICE High Level Trigger at the LHC | Comput. Phys. Commun. 242 (2019) 25 | 1812.08036 |
| 49 | R. Aaij et al. | Allen: A high level trigger on GPUs for LHCb | Comput. Softw. Big Sci. 4 (2020) 7 | 1912.09161 |
| 50 | A. Bocci et al. | Heterogeneous Reconstruction of Tracks and Primary Vertices With the CMS Pixel Tracker | Front. Big Data 3 (2020) 601728 | 2008.13461 |
| 51 | D. Vom Bruch | Real-time data processing with GPUs in high energy physics | JINST 15 (2020) C06010 | 2003.11491 |
| 52 | CMS Collaboration | Mini-AOD: A New Analysis Data Format for CMS | JPCS 664 (2015) 7 | 1702.04685 |
| 53 | CMS Collaboration | CMS Physics: Technical Design Report Volume 1: Detector Performance and Software | cms technical design report, 2006 CDS |
|
| 54 | CMS Collaboration | CMSSW on Github | link | |
| 55 | Graphcore | Intelligence Processing Unit | link | |
| 56 | Z. Jia, B. Tillman, M. Maggioni, and D. P. Scarpazza | Dissecting the Graphcore IPU architecture via microbenchmarking | 1912.03413 | |
| 57 | CMS Collaboration | Electron and photon reconstruction and identification with the CMS experiment at the CERN LHC | JINST 16 (2021) P05014 | CMS-EGM-17-001 2012.06888 |
| 58 | CMS Collaboration | Description and performance of track and primary-vertex reconstruction with the CMS tracker | JINST 9 (2014) P10009 | CMS-TRK-11-001 1405.6569 |
| 59 | CMS Collaboration | Particle-flow reconstruction and global event description with the CMS detector | JINST 12 (2017) P10003 | CMS-PRF-14-001 1706.04965 |
| 60 | oneTBB | oneAPI Threading Building Blocks | link | |
| 61 | A. Bocci et al. | Bringing heterogeneity to the CMS software framework | Eur. Phys. J. Web Conf. 245 (2020) 05009 | 2004.04334 |
| 62 | CMS Collaboration | A further reduction in CMS event data for analysis: the NANOAOD format | Eur. Phys. J. Web Conf. 214 (2019) 06021 | |
| 63 | CMS Collaboration | Extraction and validation of a new set of CMS PYTHIA8 tunes from underlying-event measurements | EPJC 80 (2020) 4 | CMS-GEN-17-001 1903.12179 |
| 64 | NVIDIA | Triton Inference Server | link | |
| 65 | gRPC Authors | gRPC | link | |
| 66 | M. Wang et al. | GPU-Accelerated Machine Learning Inference as a Service for Computing in Neutrino Experiments | Front. Big Data 3 (2021) 604083 | 2009.04509 |
| 67 | K. Pedro et al. | SonicCore | link | |
| 68 | K. Pedro et al. | SonicTriton | link | |
| 69 | K. Pedro | SonicCMS | link | |
| 70 | A. M. Caulfield et al. | A cloud-scale acceleration architecture | in 49th Annual IEEE/ACM International Symposium on Microarchitecture (MICRO), 2016 link |
|
| 71 | V. Kuznetsov | vkuznet/tfaas: First public version | link | |
| 72 | V. Kuznetsov, L. Giommi, and D. Bonacorsi | MLaaS4HEP: Machine learning as a service for HEP | ||
| 73 | KServe Authors | KServe | link | |
| 74 | NVIDIA | Triton Inference Server README (release 22.08) | link | |
| 75 | NVIDIA | Inference Server Model Analyzer | link | |
| 76 | S. D. Guida et al. | The CMS Condition Database System | JPCS 664 (2015) 042024 | |
| 77 | L. Bauerdick et al. | Using Xrootd to Federate Regional Storage | JPCS 396 (2012) 042009 | |
| 78 | CMS Collaboration | ParticleNet producer in CMSSW | link | |
| 79 | CMS Collaboration | ParticleNet SONIC producer in CMSSW | link | |
| 80 | A. Paszke et al. | Pytorch: An imperative style, high-performance deep learning library | in Advances in Neural Information Processing Systems 32, H. Wallach et al., eds., Curran Associates, Inc, 2019 link |
1912.01703 |
| 81 | ONNX | Open Neural Network Exchange | link | |
| 82 | NVIDIA | TensorRT | link | |
| 83 | M. Cacciari, G. P. Salam, and G. Soyez | The anti-$ k_{\mathrm{T}} $ jet clustering algorithm | JHEP 04 (2008) 063 | 0802.1189 |
| 84 | M. Cacciari, G. P. Salam, and G. Soyez | FastJet user manual | EPJC 72 (2012) 1896 | 1111.6097 |
| 85 | CMS Collaboration | Mass regression of highly-boosted jets using graph neural networks | CMS Detector Performance Note CMS-DP-2021-017, 2021 CDS |
|
| 86 | CMS Collaboration | Performance of missing transverse momentum reconstruction in proton-proton collisions at $ \sqrt{s}= $ 13 TeV using the CMS detector | JINST 14 (2019) P07004 | CMS-JME-17-001 1903.06078 |
| 87 | Y. Feng | A New Deep-Neural-Network--Based Missing Transverse Momentum Estimator, and its Application to W Recoil | PhD thesis, University of Maryland, College Park, 2020 link |
|
| 88 | M. Abadi et al. | TensorFlow: Large-scale machine learning on heterogeneous systems | Software available from tensorflow.org, 2015 link |
1603.04467 |
| 89 | CMS Collaboration | Identification of hadronic tau lepton decays using a deep neural network | JINST 17 (2022) P07023 | CMS-TAU-20-001 2201.08458 |
| 90 | B. Holzman et al. | HEPCloud, a New Paradigm for HEP Facilities: CMS Amazon Web Services Investigation | Comput. Softw. Big Sci. 1 (2017) 1 | 1710.00100 |
| 91 | Slurm | Slurm workload manager | link | |
|
|
Compact Muon Solenoid LHC, CERN |
|

|

|

|

|

|